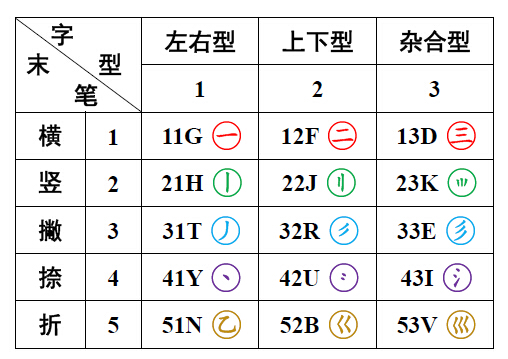
末笔识别码
汉字编码输入法的设计,要尽量减少重码,以提高输入的唯一性。但从以下两种情形我们看到,仅仅输入字根,很容易产生重码:
(1)因构字的字根相同,字型不同引起重码:
叭:口八(23 34KW)
只:口八(23 34 KW)
这个例子说明,编码中丢失了字型信息,才产生了重码。
(2)因几个字根同一键位引起重码:
沐:氵木(43 14 IS)
汀:氵丁(43 14 IS)
洒:氵西(43 14 IS)
这个例子说明,编码没有将“木、丁、西”加以区分,才产生了重码。
由以上两类例子可知,当遇到2个或3个字根构成的汉字时,为了避免编码相同(重码),既有必要提取“字型信息”,又有必要从字根上“提取笔画特征信息”用于编码。复合这两种信息的一个附加码,就是“末笔字型识别码”简称“识别码”,“识别码”只追加在由2个或3个字根构成的汉字编码中。
“识别码”是由“末笔”代号加“字型”代号构成的一个“复合附加码”。1、2、3型汉字的识别码共有15个(各有3种形式),其构成如下: